Almost everything you know — everything you can look up, fix, learn, treat — you're renting it. From companies that can raise the price, change the answer, or shut the door. And you never signed anything. That's the opening claim of the talk we gave at BSides Melbourne 2026, and it's the reason AllArkive exists.
This is the writeup version of that talk. It covers the architecture, the key engineering decisions, and the parts we're most proud of — including the thing we think separates AllArkive from every other "RAG with citations" project out there: a hallucination gate that works at the API boundary, not the prompt layer.
The internet was not supposed to be rented. It was supposed to be ours.
The problem is larger than it looks
Wikipedia is blocked in different countries at different times. Stack Overflow too. The Internet Archive has been sued into near-oblivion more than once. Google search results are increasingly AI summaries that get things wrong with great confidence. Cloud services shut down whenever the company that owns them decides they're not profitable. Every time you ask ChatGPT a question, that question is logged somewhere, and you are not the customer.
And then there's the failure mode that's rotting the information layer from inside: hallucination. Local AI right now has a well-documented problem — the model says what sounds plausible. People have built whole startups trying to fix this with clever prompts. "You are a helpful assistant who never lies, pretty please." That does not work. The model is a probability machine. Telling it not to lie is a softcoded suggestion, not a constraint.
AllArkive in one sentence
A laptop-sized library with a local AI built in, designed to keep working when the internet doesn't.
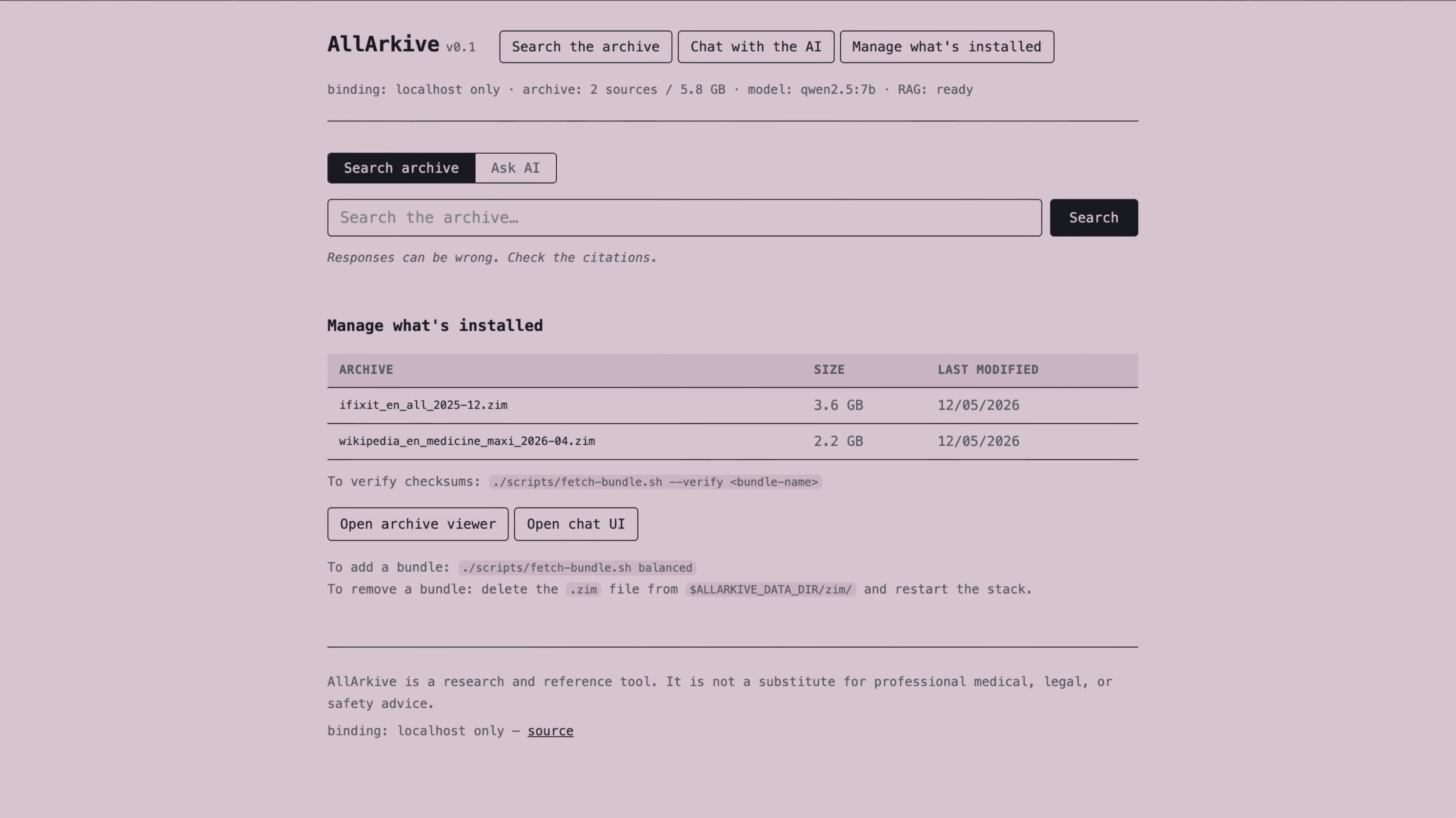
In practice: you run one command. It downloads a bundle of ZIM files — Wikipedia, WikiMed, iFixit, Stack Exchange by default. It spins up a local AI model on your machine and a web interface on localhost. You open that page in your browser, ask it a question, and it answers using only the material in your archive. Every claim has a citation. You click the citation, it takes you to the actual article — hosted locally by Kiwix. Nothing leaves your machine. No internet required after the initial download. No accounts, no telemetry, no logging.
If your internet is fine, it's a genuinely useful research tool. If your internet is not fine — censored, down, or simply unavailable — it's the most capable thing on your desk.
Three layers, each one independent
The architecture has three replaceable layers. Each one works without the others — that's not an architectural nicety, it's a resilience guarantee. You can run Kiwix alone as an offline Wikipedia reader. You can run Ollama alone as a local LLM. The RAG pipeline is the glue that makes them talk to each other.
Layer 1 — Archive (Kiwix + ZIM)
Kiwix is an open-source project that packages entire websites — Wikipedia, Stack Exchange, Project Gutenberg, iFixit — into a single-file format called ZIM. The Kiwix team maintains these files and keeps them updated. We didn't build that; we're standing on their shoulders. What we built is the tooling to fetch the right bundle, verify checksums, and serve the files through a Kiwix container — plus a FastAPI layer that can read article text from the ZIM at query time.
Layer 2 — Local AI (Ollama + Qwen 2.5)
Ollama is the cleanest way to run an open-weight model on your own machine. AllArkive defaults to Qwen 2.5 7B. It's not GPT-5. It doesn't need to be — the model isn't being asked to remember facts from training. It's being asked to synthesise a handful of relevant passages and write a coherent answer with citations. A 7B model on a laptop handles that well.
Layer 2½ — The RAG pipeline (FastAPI)
RAG — Retrieval-Augmented Generation — is the interesting bit. Instead of asking the AI a question and hoping it remembers the right answer from training, the pipeline first searches the archive for relevant articles, hands those articles to the model, and says "answer using only this." The whole retrieval step is a few hundred lines of Python and a SQLite file:
def _retrieve(query: str) -> list[dict]:
# 1. Embed the query with nomic-embed-text
emb = _embed_query(query)
packed = quant.pack(emb, _QUANTIZATION)
# 2. Dense KNN search in sqlite-vec
dense = _dense_search(packed, _TOP_K)
# 3. BM25 Xapian search across large ZIMs (hybrid mode, Pi profile)
bm25 = _bm25_search(query, _BM25_K)
# 4. Reciprocal Rank Fusion merge
merged = _rrf_merge(dense, bm25) if bm25 else dense
merged = merged[:_TOP_K]
# 5. Hydrate text lazily — chunks stored as (char_offset, char_len) pointers
# into the ZIM, not as stored text. Keeps index at ~25% of ZIM size.
passages: list[dict] = []
for p in merged:
text = _read_article_text(p["zim_name"], p["article_path"])
if text is None:
continue
snippet = text[p["char_offset"]: p["char_offset"] + p["char_len"]].strip()
if not snippet:
continue
passages.append({**p, "text": snippet})
return passagesThe vector store is sqlite-vec — a SQLite extension that adds KNN search over embeddings stored in a virtual table. No separate database daemon, no schema migrations, no running service. The entire index is one file you can rsync or put on a USB stick.
The refusal gate
Most "RAG with citations" systems enforce hallucination prevention at the prompt layer. They instruct the model not to hallucinate and trust it to comply. That's a softcoded suggestion to a probability machine.
AllArkive enforces it at the API boundary. The RAG service is an OpenAI-compatible FastAPI endpoint. Look at what happens at that boundary when retrieval returns nothing:
@app.post("/v1/chat/completions")
def chat_completions(req: _ChatRequest):
query = next(
(m.text() for m in reversed(req.messages) if m.role == "user"),
None,
)
if not query:
raise HTTPException(status_code=400, detail="no user message")
# Step 1 — vector search across the local archive
try:
passages = _retrieve(query)
except Exception as exc:
log.error("retrieval error: %s", exc)
raise HTTPException(status_code=500, detail="retrieval failed")
# Step 2 — if retrieval returns nothing, the LLM is never invoked.
# This is not a prompt instruction. This is a code branch.
# The model cannot hallucinate because it is never called.
if not passages:
answer = NO_SOURCES_TEXT
elif _SEARCH_ONLY:
answer = _format_passages_as_citations(passages, _KIWIX_PUBLIC_URL)
else:
system = build_system_prompt(passages)
llm_msgs = [{"role": "system", "content": system}] + [
{"role": m.role, "content": m.text()}
for m in req.messages if m.role != "system"
]
raw = _call_ollama(llm_msgs)
answer = rewrite_citations(raw, passages, _KIWIX_PUBLIC_URL)
if req.stream:
return StreamingResponse(_stream_text(answer), media_type="text/event-stream")
return _full_response(answer)When passages is empty, NO_SOURCES_TEXT is returned immediately and _call_ollama is never reached. This is not a prompt instruction. This is a code branch. The model cannot hallucinate because it is never invoked. The system prompt is belt-and-braces — a secondary constraint — not the actual enforcement mechanism.
NO_SOURCES_TEXT is a fixed string: "No relevant sources were found in the local archive for this question. The local knowledge base may not cover this topic. Try rephrasing, or check which bundle is installed." The user gets an honest answer about why there's no answer, not a confident fabrication.
What the model is told
When retrieval does return passages, the model receives a strict context window with explicit rules. The rules are belt-and-braces only — the real enforcement is the code branch above — but they matter for response quality:
_SYSTEM_TEMPLATE = """\
You are AllArkive's research assistant. You answer using the passages provided below.
Rules:
1. Cite every factual claim with [N] notation corresponding to the passage number.
2. Use only information from the passages. Do not add facts from outside them.
3. If a passage discusses the topic — even tangentially — synthesise what it
says and cite it. Partial answers are useful; say what the passages cover.
4. Only respond with "no sources found for this question." when the passages
have no connection to the user's topic at all.
5. Do not invent citations. If you cannot support a statement, omit it.
Passages:
{passages}
"""The [N] markers the model writes are then rewritten by a post-processing step into actual Kiwix deep-links — anchored to the exact article that supplied the passage:
def rewrite_citations(text: str, passages: list[dict], kiwix_public_url: str) -> str:
"""Turn [N] markers in model output into [[N: Article Title]](kiwix://…) links."""
base = kiwix_public_url.rstrip("/")
def _replace(m: re.Match) -> str:
n = int(m.group(1))
if n < 1 or n > len(passages):
return m.group(0)
p = passages[n - 1]
url = f"{base}/{p['zim_name']}/{p['article_path']}"
label = p.get("title") or p["article_path"].rsplit("/", 1)[-1].replace("_", " ")
return f"[[{n}: {label}]]({url})"
return re.sub(r"\[(\d+)\]", _replace, text)A reference like [2] in the model's answer becomes [[2: Wound care (WikiMed)]](http://127.0.0.1:8081/wikipedia_en_medicine/...). You can click it. It opens the full article in Kiwix, served locally.
v0.2: the indexer rewrite
v0.1 proved the concept. v0.2 made it usable on cheap hardware. Three things changed in the indexer.
Batched async embeddings — 10–30× faster
v0.1 hit the Ollama /api/embed endpoint once per chunk — one HTTP round-trip per ~800 characters of text. Indexing Wikipedia took hours on a laptop CPU. v0.2 batches chunks into groups and sends them in a single request:
async def _embed_batch(
texts: list[str], client: httpx.AsyncClient, url: str, model: str
) -> list[list[float]]:
"""v0.2: send all chunk texts in one /api/embed request.
v0.1 sent one request per chunk — 10–30× slower on CPU.
Falls back to per-item serial requests on error."""
r = await client.post(
f"{url}/api/embed",
json={"model": model, "input": texts}, # plural input list
timeout=300.0,
)
r.raise_for_status()
return r.json().get("embeddings") # one embedding per textThe speedup is 10–30× on CPU. On a laptop, the balanced bundle (~24 GB of ZIM content) now indexes in 10–25 minutes instead of hours.
int8 vector quantization — 4× smaller index
v0.1 stored embeddings as float32 arrays — 4 bytes per dimension. For the nomic-embed-text model (768 dimensions), that's 3,072 bytes per chunk. v0.2 packs them as int8 — 1 byte per dimension, 768 bytes per chunk, 4× smaller. The recall drop on cosine-normalised models is sub-1 point on MTEB benchmarks:
def pack(v: Iterable[float], mode: str) -> bytes:
"""Pack a unit-normalised vector to sqlite-vec wire bytes.
float32: 4 bytes/dim — 768-dim model = 3,072 B per chunk
int8: 1 byte/dim — 768-dim model = 768 B per chunk ← default
Sub-1-point MTEB recall drop on cosine-normalised models.
"""
vlist = list(v)
if mode == "float32":
return struct.pack(f"{len(vlist)}f", *vlist)
if mode == "int8":
# Map [-1, 1] → [-127, 127]
ints = [max(-127, min(127, int(round(x * 127)))) for x in vlist]
return struct.pack(f"{len(ints)}b", *ints)
raise ValueError(f"unsupported quantization mode: {mode}")Offset-only chunk storage — index at ~25% of ZIM size
v0.1 stored the full chunk text in the database. v0.2 stores only (char_offset, char_len) pointers into the ZIM file. The server reads the text from the ZIM at query time using the shared textproc extractor. The index drops from roughly 100% of ZIM size (in v0.1) to ~25%. On a Raspberry Pi where disk is the constraint, this is the change that makes the balanced bundle actually fit.
Five containers, one command
The whole stack is five Docker services wired together with Docker Compose:
services:
kiwix: # Layer 1 — Archive (ZIM server, bound to :8081)
ollama: # Layer 2a — AI (Qwen 2.5 inference, :11434)
open-webui: # Layer 2b — UI (chat interface, :3000)
rag: # Layer 2c — Glue (FastAPI RAG pipeline, :8000)
landing: # Layer 3 — Portal (nginx landing page, :8080)
# Open WebUI is wired via OPENAI_API_BASE_URLS.
# AllArkive appears as "allarkive-rag" in the model picker.
# Any OpenAI-compatible client works for free with zero integration code.
open-webui:
environment:
- OPENAI_API_BASE_URLS=http://rag:8000/v1
- OPENAI_API_KEYS=${RAG_API_KEY:-allarkive}
- ANONYMIZED_TELEMETRY=false
- DO_NOT_TRACK=1
- SCARF_NO_ANALYTICS=trueThe OpenAI-compatible endpoint at http://rag:8000/v1 means Open WebUI just sees a model called allarkive-rag in the model picker — alongside whatever Ollama models are installed. Any future client that speaks the OpenAI API works with zero integration code.
Getting the stack running is a single command. The bootstrap script handles platform detection, disk space checks, port-conflict resolution, bundle checksums, model pulls, and prints a status summary:
# Clone and run one command.
# The script detects your platform, checks disk space, fetches the bundle,
# starts the stack, pulls the AI model, and prints a status summary.
git clone https://github.com/allarkive/allarkive && cd allarkive
scripts/bootstrap.sh # balanced bundle (~24 GB)
scripts/bootstrap.sh --bundle minimal --pi # minimal (~5 GB) on Raspberry Pi
scripts/bootstrap.sh --bundle comprehensive \
--zim-dir /Volumes/SSD/zim # comprehensive (~411 GB) on external diskBundle tiers
Three curated bundles ship at launch. Every ZIM checksum is verified by the bootstrap script — nobody can tamper with the archive between us and you.
| Bundle | Size | Contents | Target |
|---|---|---|---|
| minimal | ~5 GB | WikiMed + iFixit repair guides | Raspberry Pi 4/5, any ~$90 board |
| balanced | ~24 GB | + Wikipedia (mini) + Stack Exchange (Unix, SuperUser, Ask Ubuntu) | Laptop — the default |
| comprehensive | ~411 GB | + Wikipedia (full, with images) + Project Gutenberg + Stack Overflow | Workstation or external drive |
At the absolute minimum — the 5 GB bundle on a Pi — you have how to fix things and how to not die. The medical wiki and iFixit are the highest-value offline resources for an actual emergency.
Honest limits
We didn't build a magic box. We built a useful tool with real limits, and we're upfront about both.
What it protects against
- Your internet going down. Outages, censorship, ISP failures — the archive keeps working.
- Cloud rug-pulls. Services shut down when they're not profitable. Your local copy doesn't.
- Source censorship. If Wikipedia is blocked where you are, your downloaded copy isn't. After initial download, all traffic is local.
- Surveillance. What you search for never leaves your machine. No logs, no telemetry, no analytics.
- Hallucination (at the API layer). The model cannot fabricate because it is not called when there's nothing to cite from.
What it does not protect against
- A targeted attacker with code execution on your laptop. AllArkive binds everything to 127.0.0.1 by default, but it's not a security product.
- Archive staleness. Wikipedia changes every second; your copy is a snapshot. The citations help you verify.
- Forced disclosure. Someone compelling you to hand over your laptop is out of scope.
- Custom bundles with bad content. If you build a custom bundle from untrusted sources, that's on you.
- Model answers being absolute. Citations are how you verify. We print a reminder after every response.
This is a research tool. It is not your doctor. It is not your lawyer. It is a really, really good reference library with a librarian attached.
Who we built this for
Honestly, us first. Both of us have family in places where the internet is not as friendly as Melbourne. That was the original itch. But as we talked to more people, the picture got larger.
Librarians, who are worried about digital preservation. Teachers in remote schools with unreliable connectivity. Journalists in countries where Wikipedia is blocked. Parents who want their kids to look things up without algorithmic pipelines. People in rural Australia where the NBN goes down for a week and nothing works. People who cannot afford a thousand-dollar-a-month AI subscription and should not need one to have access to what should just be theirs.
Wikipedia is free. The license permits exactly this use. The tools to run a local AI are free. The only thing missing was someone tying them together so a normal person can install it without a CS degree.
You can run a useful AI on a Raspberry Pi now. You can have all of Wikipedia in your pocket. You can have a research assistant that nobody is logging. These are not science fiction. They're just not packaged.
Build with us
AllArkive is AGPL-3.0 — deliberately, not by default. GPL leaves a SaaS loophole: you can run GPL software as a hosted service without releasing your changes. AGPL closes it. A company cannot host AllArkive without open-sourcing their modifications.
There is no funding round. There will never be a SaaS version. There will never be telemetry. We are two people who built something we needed and decided to give it away properly.
We need people to break our installer on weird hardware. We need translators and librarians to help curate non-English bundles. We need security people to tear apart our threat model. If you find something wrong, we want to know. The repository is at github.com/allarkive/allarkive.
It will always be free. It will always be inspectable. If we both get hit by a bus, somebody else can fork it and keep going.